

Hackathon: 24 hours on Data Mashup for Big Data Analytics in a Smartening World
Thank you to everyone who participated and made the hackathon a success! There were 24 participants along with 2 subject matter experts for tutorial and hands-on sessions with 3 other judges. Congratulations to our winners!

Hackathon Organizers

Hackathon Tutorial

First Place Winners

Second Place Winners
Monday July 23, 9:30am – 5:30pm, Meeting 12F
Big Data is a collection of data so large, so complex, so distributed, and growing so fast (or 5Vs- volume, variety, velocity, veracity, and value). It has been known for unlocking new sources of economic values, providing fresh insights into sciences, and assisting on policy making. However, Big Data is not practically consumable until it can be aggregated and integrated into a manner that a computer system can process. For instance, in the Internet of Things (IoT) environment, there is a great deal of variation in the hardware, software, coding methods, terminologies and nomenclatures used among the data generation systems. Given the variety of data locations, formats, structures and access policies, data aggregation has been extremely complex and difficult. More specifically, a health researcher was interested in finding answers to a series of questions, such as “How is the gene ‘myosin light chain 2’ associated with the chamber type hypertrophic cardiomyopathy? What is the similarity to a subset of the genes’ features? What are the potential connections among pairs of genes”? To answer these questions, one may retrieve information from databases such as the NCBI Gene database or PubMed database. In the Big Data era, it is highly likely that there are other repositories also storing the relevant data. Thus, we are wondering:
- Is there an approach to manage such big data, so that a single search engine available to obtain all relevant information drawn from a variety of data sources and to act as a whole?
- How do we know if the data provided is related to the information contained in our study?
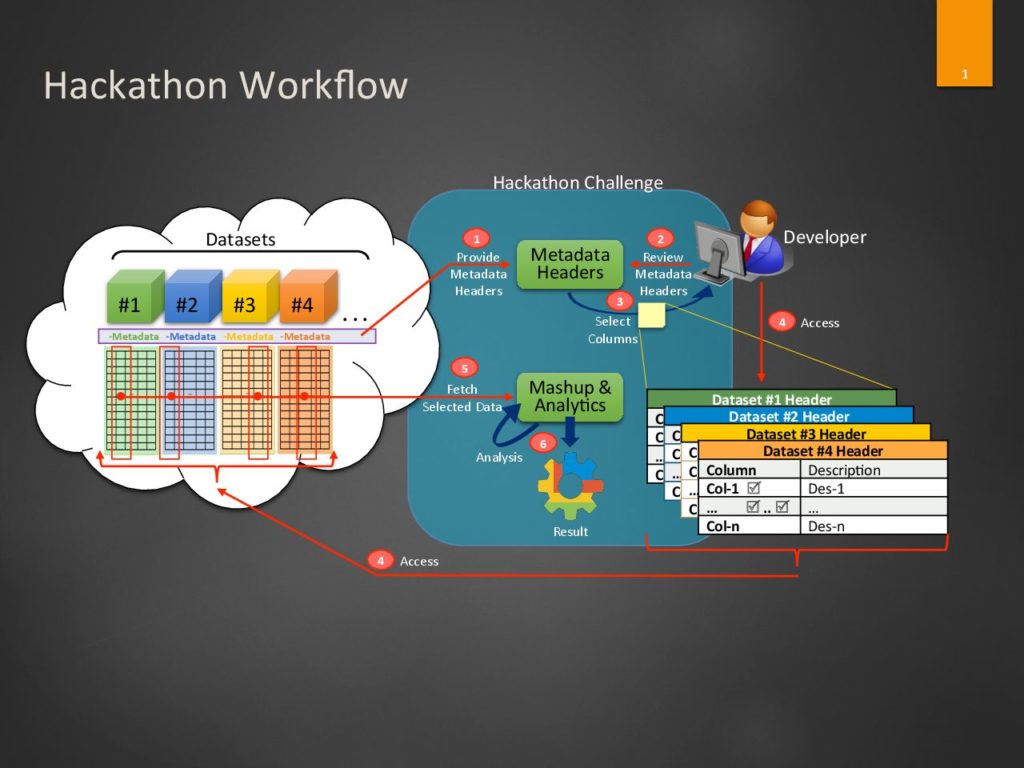
Hackathon Objective: The goal of the hackathon is to address the Big Data variety challenges in a smartening world. The aim is to explore how to enable data integration/mashup among heterogenous datasets from diversified domain repositories and to make data discoverable, accessible, and re-usable through a machine readable and actionable standard data infrastructure.
Hackathon Challenges: The task for the hackathon is to develop data mashup scheme to cross reference any given datasets and apply statistical analysis, machine learning, and visualization tools to statistically analyze and develop predictive models to draw meaningful results. To achieve the goal, think outside the box and come up with innovative ideas that bring more value out of the data.
Hackathon Participants: All participants must be registered via the COMPSAC main conference website and attend physically. You may register as a team (up to four per team) or an individual (we will place you on a team). Each participant brings his/her own laptop with all the necessary computing tools. No remote computing resources are allowed. All implementation must be based on the original work.
Please visit https://bigdatawg.nist.gov/bdgmm_compsac2018.html for the most up to date information on the Hackathon.
The Hackathon is affiliated with the Big Data Governance and Metadata and Management Workshop (BDGMM 2018).
Hackathon Chair
Wo Chang, Chair of IEEE Big Data Governance and Metadata Management, National Institute of Standards & Technology
Email: wchang@nist.gov
Hackathon Evaluation Team
David Belanger, Chair of IEEE Big Data Technical Community, Stevens Institute of Technology
Mahmoud Daneshmand, Vice-Chair of BDGMM, Steven Institute of Technology
Kathy Grise, Senior Program Director, Future Directions, IEEE
Joan Woolery, Senior Project Manager, Industry Connections, IEEE Standards Association, IEEE
Cherry Tom, Emerging Technologies Initiatives Manager, IEEE Standards Association, IEEE